Jisu Han
Hi, I'm Jisu! I am a first-year Ph.D. student in the Interdisciplinary Program in Artificial Intelligence (IPAI) at Seoul National University, and a member of the M.IN.D Lab, where I am fortunate to be advised by Taesup Moon.
I obtained my Master's Degree in the Graduate School of AI at KAIST, in the Humanoid Generalization Lab directed by Beomjoon Kim. I received my Bachelor's Degree in Computer Science from Ewha Womans University. I was fortunate to work with Joseph Lim and Jaeheung Park.

The future I imagine looks like the coexistence portrayed in Detroit: Become Human — robots that don't just follow commands, but live alongside us, reading a room and adjusting as a person would. By skill here I mean an abstraction over how an agent gets something done — not a single fixed motion, but something that can be represented, grounded in a situation, and changed when it doesn't work. Cognitive science describes human skill this way too: under schema theory, a person reusing a "carry this" skill never repeats the same motion — they hold a flexible schema, read the context, and adjust, or fail and adjust the schema itself. I want robots to hold skills the same way: not as fixed scripts, but as abstractions that are represented, grounded in context, and updated through experience. Concretely, I study how agents represent, ground, and update skills along this loop.
I look at how that plays out unevenly across LLMs, VLMs, and VLAs, and ask how their strengths can cover one another's gaps: LLMs and VLMs each handle part of the loop — representing and updating in language, or grounding in what's seen — but neither has to act, or live with the consequences of failing. VLA is where it becomes one piece: a single system that must represent, ground, and update together, in real time, under real physical consequence — the loop, embodied.
Each paper below is tagged by where it sits on that loop.
* denotes equal contribution
TL;DR
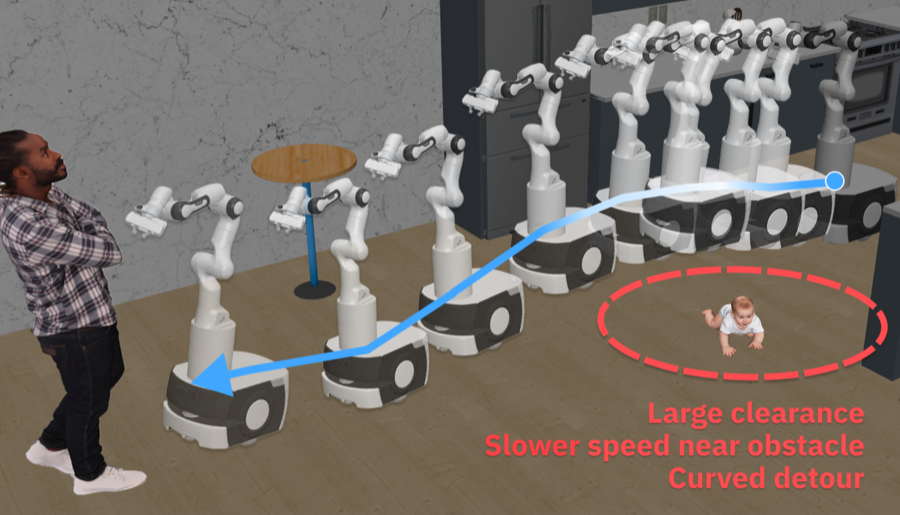
Benchmarks whether foundation-model robot policies adjust low-level navigation to safety context. It uses matched scenes where obstacle semantics or safety demand changes, exposing failures like treating a baby too similarly to a rigid object.
TL;DR
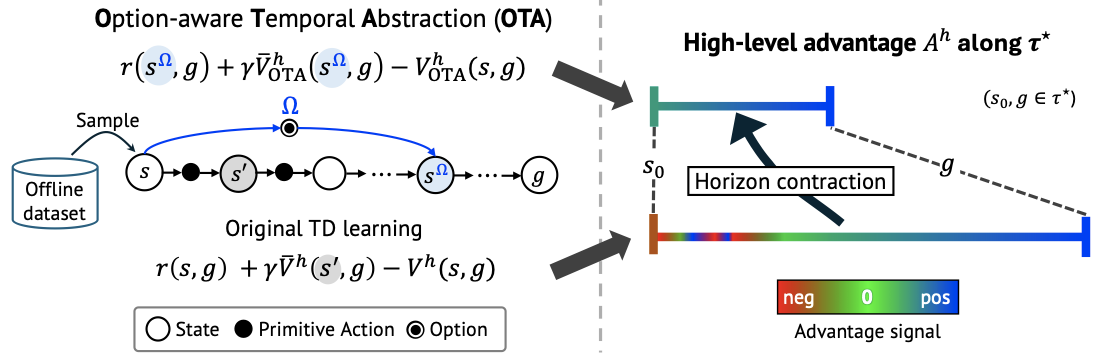
Introduces option-aware, temporally abstracted value learning for offline goal-conditioned RL. By reasoning over options instead of only primitive actions, the agent can make more reliable long-horizon goal-reaching decisions from static datasets.